Jag har tidigare visat hur man kan göra datavisualiseringar med Plotly. Både vanliga diagram och animerad grafik. Plotly Express är otroligt smidigt, men vill man göra lite krångligare saker behöver man använda Plotly Graph Objects. Inte tvunget krångligare faktiskt, utan om man vill kunna styra vissa saker mer i detalj. Plotly Express är väldigt bra på att räkna ut det bästa sättet att jobba med dina data. Du anger minimalt med konfigurationsuppgifter, px bara fixar! Vill man som i exemplet jag kommer att visa, ha två grafer ovanpå varandra med en gemensam x-axel behöver man använda Plotly GO. Man kan förstås utöka konceptet och bygga på med så många grafer man behöver. Tanken är att du ska kunna göra det här själv med dina data.
Förutsättningar
Allt du behöver veta innan vi kan börja finns beskrivet i inlägget om Plotly. Du måste alltså ha både Python och Plotly installerat. Du behöver även modulen/paketet Pandas. Har du redan med framgång använt Plotly Express blir det här plättlätt. Men kaffe kanske du ska fixa dig en kopp i alla fall, för varför inte?
Koden i sin helhet samt datan som behövs till det här exemplet finns sist i inlägget. Ladda ner Excelfilen och häng med i exemplet!
Bygga koden
Vi kör som vanligt; du öppnar det program du brukar använda för att skripta/koda och så kör vi igång.
Imports
Vi behöver importera följande:
import pandas as pd import plotly import plotly.express as px import plotly.graph_objects as go from plotly.subplots import make_subplots
Pandas för att kunna importera och hantera datan; Plotly förstås och så Plotly Graph Objects. Jag har med Plotly Express ändå här, men det enda jag använder det till är färgerna på kurvorna. Vi importerar även make_subplots från plotly.subplots för att kunna dela upp visualiseringen i delgrafer. I mitt exempel kommer det bara bli 2 stycken men jag ska visa konceptet så att du ser hur du kan ha t ex 3 på längden och 3 på tvären 😉
Dataframes
När nu alla paket som vi behöver är med på tåget är det dags att importera våra data. Det kan man göra på många olika vis. Jag har valt att jobba med en Excelfil i det här exemplet. Men det går förstås utmärkt att knappa in sin “dataframe” för hand direkt i kodfilen eller använda något annat format som CSV eller json. Lämna gärna en kommentar om det är något du önskar en genomgång av.
df = pd.read_excel("TBE_SVE.xlsx")
Som du kanske ser så ligger filen i samma mapp som Pythonfilen. Om det inte är så för dig måste du ändra sökvägen i koden ovan.
Make subplots
Nästa steg är att ställa upp och skapa delgraferna eller subplots. X-axeln kommer vara gemensam (shared_xaxes=True) men jag vill ha 2 y-axlar. Här bestämmer jag även att jag vill ha 2 rader (rows) och 1 kolumn (cols). Med vertical_spacing=0.05 bestämmer jag hur mycket luft jag vill ha mellan den övre och den undre grafen. Om jag har mer än en kolumn och vill bestämma hur stort utrymmet mellan dem ska vara heter det horizontal_spacing.
fig = make_subplots(rows=2, cols=1,
shared_xaxes=True,
vertical_spacing=0.05)
Det är här du ska utöka konceptet om det är vad du tänkt dig. T ex rows=3, cols=3 ger förstås 9 rutor.
Lägg till respektive kurva
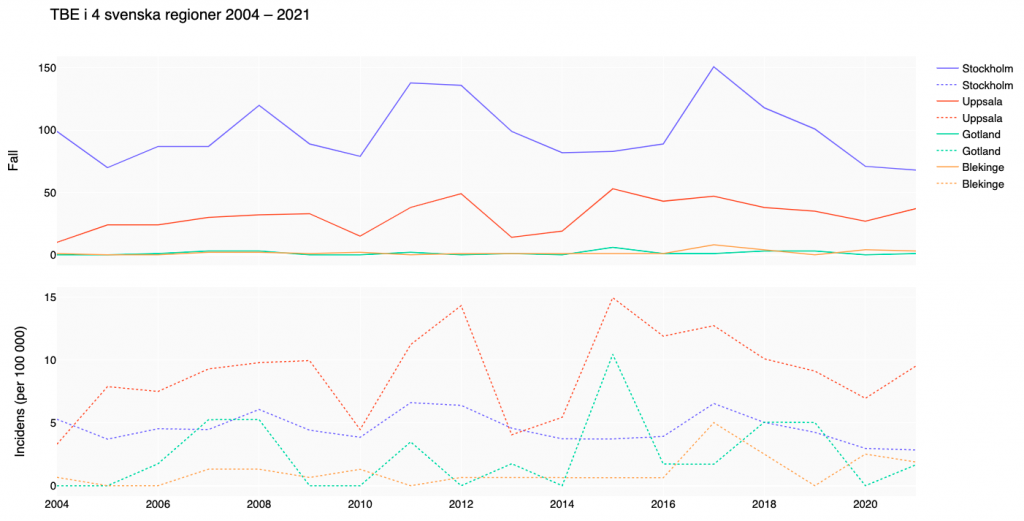
Nu är det dags att ordna med självaste strecken 😉 Än så länge har vi inte riktigt visat något. I mitt exempel har jag data om antalet fall av tick-borne encephalitis (TBE) i fyra svenska regioner från 2004 till september 2021. Jag har även information om den årliga incidensen som jag vill ska visas under grafen med antalet totala fall. Grafen över antalet totala fall i Stockholm skapas genom att lägga till en så kallad trace (SV: kurva):
fig.add_trace(
go.Scatter(x=df["year"], y=df["f_sthlm"],
name="Stockholm",
line=dict(color=px.colors.qualitative.Plotly[0],
width=1.5),
mode='lines'),
row=1, col=1),
Tolkning av koden blir något i stil med: Gör en figur; lägg till en trace och det ska vara ett spridningsdiagram (EN: scatter plot).
På x-axeln ska det vara data från kolumnen “year” i dataframen df. På y-axeln vill vi ha datan från kolumnen “f_sthlm” i Excelbladet. Namnet på kurvan ska vara Stockholm och kurvans färg anges i det här fallet med Plotlys inbyggda färgskalor (https://plotly.com/python/discrete-color/) men det går lika bra att ange en hexkod (hexadecimala talsystemet). Bredden på linjen ska vara 1,5 pixlar och jag vill ha en solid linje = “lines”. Underst, eller egentligen i slutet av raden, bestämmer jag i vilken graf jag vill ha den här kurvan. Resultatet av row=1 och col=1 blir överst av de två.
I den undre grafen vill jag visa incidensen. Därför behöver jag byta ut “f_sthlm” mot vad jag nu döpt incidenskolumnen till i min Excelfil (“i_sthlm”).
fig.add_trace(
go.Scatter(x=df["year"], y=df["i_sthlm"],
name="Stockholm",
line=dict(color=px.colors.qualitative.Plotly[0],
width=1.5,
dash='dot'), mode='lines'),
row=2, col=1),
För den här kurvan står det dash=’dot’ men fortfarande mode=’lines’. Resultatet blir en streckad linje. Sist behöver vi ange i vilken graf kurvan hör hemma, dvs på rad 2.
Detta förvarande upprepas sedan med de övriga 3 regionerna Uppsala, Gotland och Blekinge. Hela koden finns i slutet av inlägget.
Snygga till
Då var det bara finliret kvar 🙂
För att namnge de båda y-axlarna uppdaterar vi dem med title_text och anger vilken rad och kolumn vi menar:
fig.update_yaxes(title_text="Fall", row=1, col=1) fig.update_yaxes(title_text="Incidens (per 100 000)", row=2, col=1)
Den här raden ordnar med en mer behaglig bakgrundsfärg. Du bestämmer förstås själv 😛
fig.layout.plot_bgcolor = "#FAFAFA"
Hela alstret ska förstås få ett förklarande namn:
fig.update_layout(title_text="TBE i 4 svenska regioner 2004 – 2021")
Sist ändrar vi teckensnitten och teckenstorleken i rubriken. Det behövs förstås inte om du är nöjd med originalkonfigurationen.
fig.update_layout(
font=dict(
family="Helvetica",
size=15,
color="black"
)
)
Visa figuren
Vi avslutar som vanligt med att faktiskt visa figuren:
fig.show()
Kör koden i terminalen och se till att Excelfilen finns där du angett att den ska finnas.
$ python3 TBE_epi_graph_obj.py
Så småningom ska alstret visas i standardwebbläsaren. Plotly har fixat rimliga skalor på axlarna åt oss. Du kan trycka på en regions kurva i listan till höger om diagrammet och därmed släcka den. Klicka igen för att få tillbaka kurvan. Det är mycket praktiskt om det skulle vara så att kurvorna ligger lite ovanpå varandra eller du vill kunna jämföra bara några stycken. Eller om en kurva går mycket högre än de andra, då ändras skalan automagiskt när jag släcker det extrema landet och man ser de andra betydligt bättre. Det finns också möjlighet att zooma in på en valfri del. Klicka omkring lite ska du få se!
Som av en händelse har vi här också visat varför det är viktigt att i epidemiologiska sammanhang ha koll på incidensen och inte bara det totala antalet fall av en smittsam sjukdom. Titta på den övre kurvan, totalt antal fall. Stockholm har flest antal fall av TBE under alla de år som är med i den här statistiken.
Titta sedan på den undre kurvan. Här är det istället Uppsala som ligger överst de allra flesta åren. Det beror på att Uppsala har fler fall sett till invånarantalet. Per 100 000 personer är det fler som drabbas av TBE i Uppsala än i Stockholm. Kanske ser du också att Gotland ser ut att ha få fall per år, men sett till att befolkningen på Gotland inte är så stor var de relativt hårt drabbade av TBE under 2015. Under det året drabbades alltså 0,01 % (eller 0,1 promille) av gotlänningarna av TBE.
Koden och datan
Ladda ner Excelfilen här.
Hela koden
# imports
import pandas as pd
import plotly
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# data frame xlsx
df = pd.read_excel("TBE_SVE.xlsx")
# subplot for 2 y-axes
fig = make_subplots(rows=2, cols=1,
shared_xaxes=True,
vertical_spacing=0.05)
# plots - tot - sthlm
fig.add_trace(
go.Scatter(x=df["year"], y=df["f_sthlm"],
name="Stockholm",
line=dict(color=px.colors.qualitative.Plotly[0],
width=1.5),
mode='lines'),
row=1, col=1),
# plots - inc - sthlm
fig.add_trace(
go.Scatter(x=df["year"], y=df["i_sthlm"],
name="Stockholm",
line=dict(color=px.colors.qualitative.Plotly[0],
width=1.5,
dash='dot'), mode='lines'),
row=2, col=1),
# plots - tot - uppsala
fig.add_trace(
go.Scatter(x=df["year"], y=df["f_uppsala"],
name="Uppsala",
line=dict(color=px.colors.qualitative.Plotly[1],
width=1.5),
mode='lines'),
row=1, col=1),
# plots - inc - uppsala
fig.add_trace(
go.Scatter(x=df["year"], y=df["i_uppsala"],
name="Uppsala",
line=dict(color=px.colors.qualitative.Plotly[1],
width=1.5,
dash='dot'), mode='lines'),
row=2, col=1),
# plots - tot - gotland
fig.add_trace(
go.Scatter(x=df["year"], y=df["f_gotland"],
name="Gotland",
line=dict(color=px.colors.qualitative.Plotly[2],
width=1.5),
mode='lines'),
row=1, col=1),
# plots - inc - gotland
fig.add_trace(
go.Scatter(x=df["year"], y=df["i_gotland"],
name="Gotland",
line=dict(color=px.colors.qualitative.Plotly[2],
width=1.5,
dash='dot'), mode='lines'),
row=2, col=1),
# plots - tot - blekinge
fig.add_trace(
go.Scatter(x=df["year"], y=df["f_blekinge"],
name="Blekinge",
line=dict(color=px.colors.qualitative.Plotly[4],
width=1.5),
mode='lines'),
row=1, col=1),
# plots - inc - blekinge
fig.add_trace(
go.Scatter(x=df["year"], y=df["i_blekinge"],
name="Blekinge",
line=dict(color=px.colors.qualitative.Plotly[4],
width=1.5,
dash='dot'), mode='lines'),
row=2, col=1)
# y-axes titles
fig.update_yaxes(title_text="Fall", row=1, col=1)
fig.update_yaxes(title_text="Incidens (per 100 000)",
row=2, col=1)
# background color
fig.layout.plot_bgcolor = "#FAFAFA"
# title
fig.update_layout
(title_text="TBE i 4 svenska regioner 2004 – 2021")
# text font mm
fig.update_layout(
font=dict(
family="Helvetica",
size=15,
color="black"
)
)
# show figure
fig.show()
# offline
plotly.offline.plot(fig, filename='TBE_epi_go.html')
Observera att indragningarna till nästa rad inte alltid visas korrekt! När du bryter en rad som egentligen hör samman med den förra gör du en indragning med fyra blanksteg (eller en tabb) för att python ska förstå hur det hela hänger ihop.
Vidare läsning
https://plotly.com/python/subplots/
 1
1