Innehållsförteckning
Hur gör man ett eget ordmoln (word cloud)? Det finns massor med sidor på nätet där du kan skapa egna ordmoln över de vanligast förekommande orden i en vald text (t ex här). Men hur kul är det? Såklart ska vi göra det själva – i Python.
Om du mot förmodan aldrig sett ett ordmoln förut så är det en bild baserad på vilka ord som förekommer flest gånger i en text. Vanligare ord = större typsnitt på ordet i bilden. Vilka ord använder jag/författaren mest? Det kan bli en bra och nyttig illustration över något man nästan inte ville veta. Man har sina upphängningar 🙈
Skapa ordmoln
Lämplig text
Du behöver förstås en lämplig text att basera ordmolnet på. Varför inte din uppsats eller en labbrapport du kämpat med och är stolt över? Det skulle också kunna vara en bok som du har den råa texten till. Men då behöver man fundera ett varv på eventuell copyright och såna saker. Det är ändå roligast om det är din egen text.
Texten behöver vara tillgänglig i txt-format. Utgår du ifrån t ex en Word-fil behöver du konvertera filen till .txt. Det kan du göra genom att välja Spara som… Oformaterad text (.txt). Har du en pdf du vill använda är det kanske enklast att kopiera hela alltet och klistra in i ett Worddokument. Formateringen, hur det hela ser ut med radbrytningar osv är helt ointressant. Det enda vi bryr oss om är att alla ord är med.
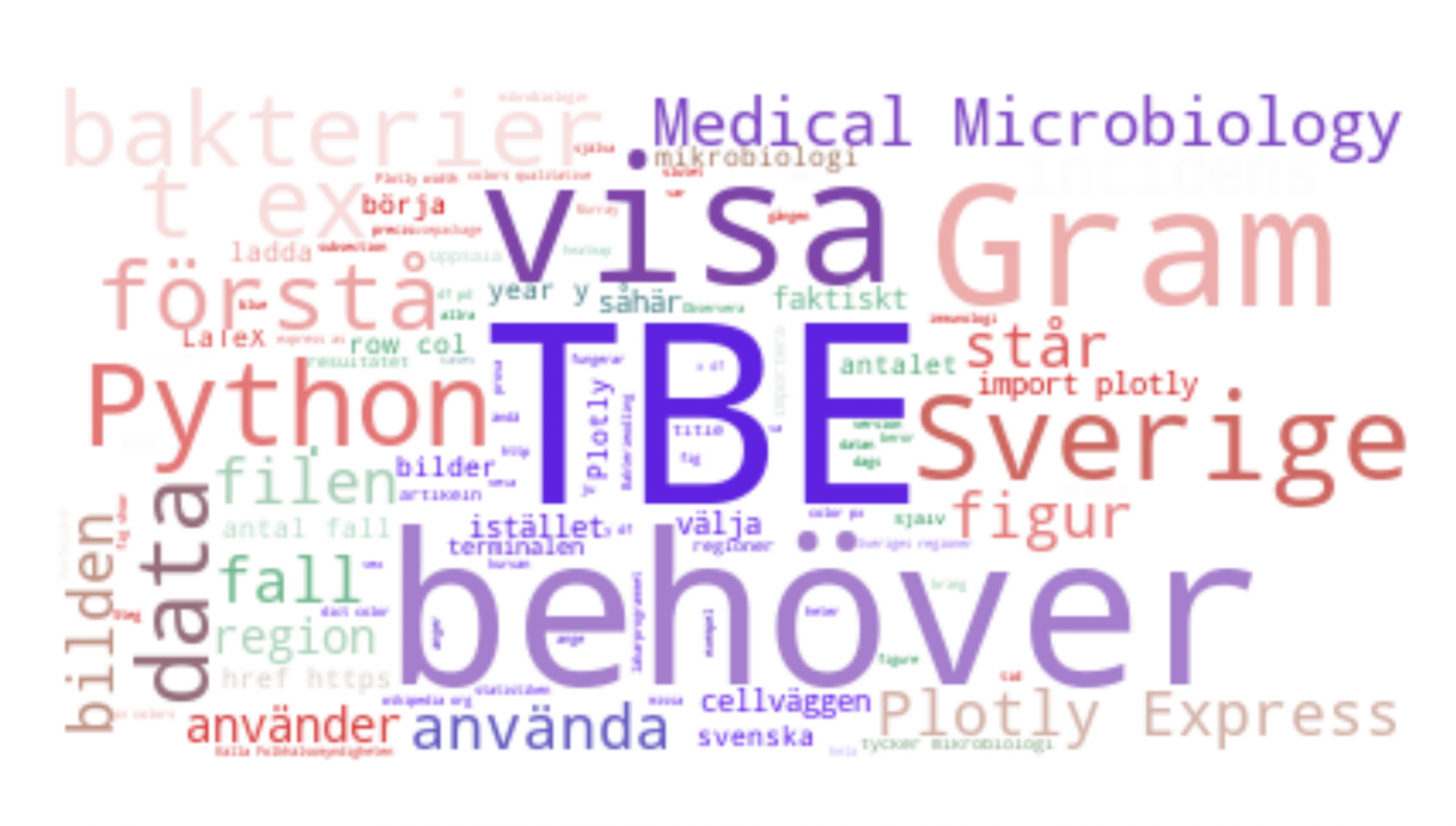
Jag har valt att göra en textfil av alla artiklarna på Mikroblobben. Det blir en bra illustration över vad bloggen handlar om och jag får en påminnelse om vilka saker/ord jag är tjatig med på köpet.
Apropå böcker får du gärna ta en titt på artikelserien om hur bra böckerna i mikrobiologi som rekommenderas som kurslitteratur på de svenska läkarprogrammen är.
Bild som färgpalett
Som du ser så har orden olika färger. Det beror på att färgskalan är baserad på en bild. Om man valt en bok skulle man t ex kunna använda omslaget som bas för färgerna i ordmolnet. Nu har inte jag nåt riktigt omslag till bloggen. Istället har jag valt en bild från Wikipedia som jag tyckte hade starka och fina färger. Bilden visar en gramfärgning, som du kan läsa mer om i artikelserien om både metoden och mannen bakom upptäckten. Färgerna blir lite blekare än de är i originalet, så mitt tips är att ta en bild med starka färger.
Stoppord
Vad tror du händer om man gör ett ordmoln av en längre text? Vilka ord kommer bli vanligast? Förmodligen kommer helt ointressanta mellanord dominera. Här är en bild på ett ordmoln över Mikroblobben där alla ord är med i analysen:

Det blir ju supersnyggt men inte så spännande. Det skulle kunna vara vilken text som helst och säger inte mycket om innehållet på bloggen. Man blir lite besviken, eller hur?!
Det vi behöver göra är att utesluta alla meningslösa mellanord från vår analys. Ord som “att” och “och” måste ju uppenbarligen bort. Vi kan kalla dem stoppord. Lyckligtvis finns det andra som redan haft och löst det här problemet. Det finns färdiga listor på ord att plocka bort.
För att generera en sådan lista i Python kan man t ex använda paketet advertools. Om du, som jag, aldrig använt just det här paketet behöver du börja med att installera det:
pip install advertools
När det är klart skapar vi ett litet skript för att få ut en lista över svenska ord att plocka bort:
När man kör det har skriptet i terminalen blir resultatet en lista liknande den här:
Jag har klippt bort allt efter ‘dig’. Listan är ganska lång och det är inte meningsfullt att visa alltihop här och nu. Du förstår konceptet!
Importera paket
Då är vi redo att börja på koden till det här projektet. Vi börjar med att importera alla paket som vi behöver. Det är praktiskt att ha dem samlade överst i skriptet:
Första paketet, pathlib, hjälper oss att hitta till filer. Wordcloud är precis vad det låter som, ett paket för att skapa ordmoln. Vi behöver även Mathplotlibs Pyplot för att kunna jobba med och ändra figurer, i vårt fall bilder. Numpy har vi också med för att kunna manipulera bilden som ska vara vår färgpalett. Paketet PIL (Python Image Library) handlar också om bildmanipulation. Läs gärna mer om det här. Har du hängt med på bloggen och utgått ifrån artikeln om Python och Plotly så kommer du fattas en del av de här paketen. Det löser man på samma sätt som för advertools ovan med “pip install paketnamn“.
Hämta texten
Nu ska vi specificera var vi gjort av vår textfil. Det gör vi med pathlib såhär:
Jag har också valt att skriva ut sökvägen i terminalen för att kunna se att det blev rätt. Som vanligt är det viktigt att sökvägen är rätt och pekar på den mappen du faktiskt har filen i. I mitt exempel har jag gjort det enkelt för mig. Filen finns i samma mapp som mitt Pythonskript.
Färgpaletten
Det är dags att dra in bilden som ska få vara vår färgpalett. Som du ser heter min bild (den jag sparade från Wikipedia ovan) 3.png.
Skapa ordmolnet
Nu drar vi in texten och listan med stopporden som vi vill få bort för att vi ska få nånting vettigt ut av det här:
Återigen har jag inte tagit med hela listan. Den fortsätter ogenerat ett tag till efter “…”.
Sen skapar vi själva figuren med följande kod:
Det som händer här är att vi skapar en variabel (wordcloud) som använder paketet WordCloud som vi importerade i början. WordCloud får sedan jobba med följande info: vi vill att stopporden ska vara de vi stoppat i variabeln “stopwords“. Bakgrundsfärgen ska vara vit (du gör som du vill, svart eller nån annan mörk färg som passar din färgpalett skulle också vara snyggt) och läget (mode) ska vara RGBA. Med “.generate” genererar vi texten till ordmolnet.
Efter det har vi raden som börjar med variabeln “image_colors“. Där använder vi modulen från paketet wordcloud för att skapa vår färgskala utifrån den bild vi valde som underlag och som vi bearbetade med Numpy (np.array) i variabeln “mask” ovan.
På nästa rad bestämmer vi, som du säkert misstänker, hur stor bild vi vill att molnet ska bli. Och därefter ändras färgerna på vår molntext. Sist i det här kodblocket stänger vi av visningen av skalan/axlarna. För det skulle ju inte bli så snyggt att ha med, det ska inte märkas att det är en typ av diagram.
Spara bilden
De sista två raderna i vårt fina molnskript ordnar så att bilden faktiskt sparas och visas:
Vi bestämmer bland annat namnet på bildfilen och att vi vill att det ska vara png-format. Det andra behöver du inte ändra om du inte har särskilda önskemål.
Resultatet
Det var allt. Då återstår bara att se hur det blev! Du hittar hela koden på Mikroblobbens Github-sida. Och för att få se ditt alster kör du skriptet i terminalen, precis som vi brukar: python mitt_ordmoln.py.
Lycka till och dela gärna med dig av ditt alster i kommentarerna!
 2
2